Chapter 2 Literature Review
I use a structured approach to narrow down recent and relevant literature. In this chapter, we take a glimpse of prior research in this field and review the relevant literature in line with factors identified in Essentials of Counterterrorism chapter. In the last part, we examine the literature gap and relevance with our research topic.
2.1 Overview of prior research
Scientific research in the field of terrorism is heavily impacted by research continuance issue. According to (Gordon, 2007), there is indeed a growing amount of literature in terrorism field but the majority of contributors are one-timers who visit and study this field, contribute few articles, and then move to another field. Researcher (Schuurman, 2018) points out another aspect and suggests that terrorism research has been criticized for a long time for being unable to overcome methodological issues such as high dependency on secondary sources, corresponding literature review methods and relatively insufficient statistical analyses. This argument is further supported a number of prominent researchers in this field. Compared to other similar fields such as criminology, terrorism research suffers a lot due to complications in data availability, reliability and corresponding analysis to make the research useful to policymakers (Brennan, 2016).
2.1.1 Harsh realities
One of the harsh realities in terrorism research is that the use of statistical analysis is fairly uncommon. In late 80s, (Jongman, 1988) in his book “Political Terrorism: A New Guide To Actors, Authors, Concepts, Data Bases, Theories, And Literature” identified serious concerns in terrorism research related to methodologies used by the researcher to prepare data and corresponding level of analysis. (A. Silke, 2001) reviewed the articles in terrorism research between 1995 and 2000 and suggests that key issues raised by (Jongman, 1988) remains unchanged in that period as well. Their research findings indicate that only 3% of research papers involved the use of inferential analysis in the major terrorism journals. Similar research was carried out by (Lum, Kennedy, & Sherley, 2006) on quality of research articles in terrorism research and their finding suggests that much has been written on terrorism between 1971 to 2003 and around 14,006 articles were published however the research that can help/support counterterrorism strategy was extremely low. This study also suggests that only 3% of the articles were based on some form of empirical analysis, 1% of articles were identified as case studies and rest of the articles (96%) were just thought pieces.
Very recently, researcher (Schuurman, 2018) also conducted an extensive research to review all the articles (3442) published from 2007 to 2016 in nine academic journals on terrorism and provides an insight on whether or not the trend (as mentioned) in terrorism research continues. Their research outcome suggests an upward trend in on the use of statistical analysis however major proportion is related to descriptive analysis only. They selected 2552 articles for analysis and their findings suggest that:
- only 1.3% articles made use of inferential statistics
- 5.8% articles used mix of descriptive and inferential statistics
- 14.7% articles used descriptive statistics and
- 78.1% articles did not use any kind of statistical analysis
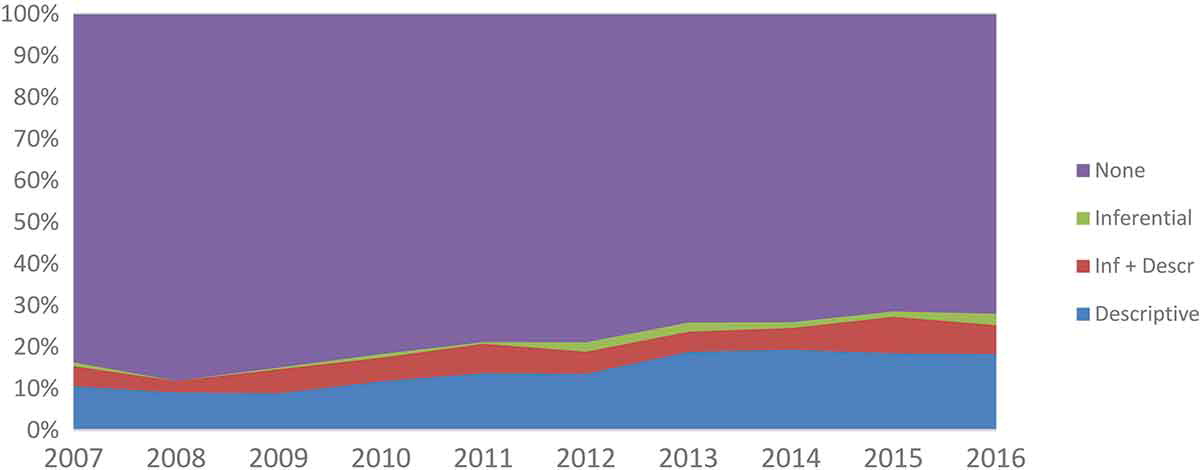
Figure 2.1: Use of statistics in terrorism research from 2007 to 2016
(Schuurman, 2018)
2.1.2 Review of relevant literature
In this section, we take a look at previous research that is intended toward counterterrorism support while making sure that the chosen research article/ literature contains at least some form of statistical modeling.
Simple linear regression was one of the approaches for prediction models in early days but soon it was realized that such models are weak in capturing complex interactions. The emergence of machine learning algorithms and advancement in deep learning made it possible to develop fairly complex models however country-level analysis with resolution at year level contributes majority of research work in conflict prediction (Cederman & Weidmann, 2017).
(Beck, King, & Zeng, 2000) carried out a research to stress the important of the causes of conflict. Researchers claim that empirical findings in the literature of global conflict are often unsatisfying, and accurate forecasts are unrealistic despite availability immense data collections, notable journals, and complex analyses. Their approach uses a version of a neural network model and argues that their forecasts are significantly better than previous effort.
In a study to investigate the factors that explain when terrorist groups are most or least likely to target civilians, researcher (Heger, 2010) examines why terrorist groups need community support and introduces new data on terrorist groups. The research then uses logit analysis to test the relationship between independent variables and civilian attacks between 1960-2000.
In a unique and interesting approach, a researcher from ETH Zürich (Chadefaux, 2014) examines a comprehensive dataset of historical newspaper articles and introduces weekly risk index. This new variable is then applied to a dataset of all wars reported since 1990. The outcome of this study suggests that the number of conflict-related news items increases dramatically prior to the onset of conflict. Researcher claims that the onset of a war data within the next few months could be predicted with up to 85% confidence using only information available at the time. Another researcher (Cederman & Weidmann, 2017) supports the hypothesis and suggests that news reports are capable to capture political tension at a much higher temporal resolution and so that such variables have much stronger predictive power on war onset compared to traditional structural variables.
One of the notable (and publicly known) researches in terrorism predicted the military coup in Thailand 1 month before its actual occurrence on 7 May 2014. In a report commissioned by the CIA-funded Political Instability Task Force, researchers (Ward Lab, 2014) forecasted irregular regime changes for coups, successful protest campaigns, and armed rebellions, for 168 countries around the world for the 6-month period from April to September 2014. Researchers claim that Thailand was number 4 on their forecast list. They used an ensemble model that combines seven different split-population duration models.
Researchers (Fujita, Shinomoto, & Rocha, 2016) use high temporal resolution data across multiple cities in Syria and time-series forecasting method to predict future event of deaths in Syrian armed conflict. Their approach uses day level data on death tolls from Violations Documentation Centre (VDC) in Syria. Using Auto-regression (AR) and Vector Auto-regression (VAR) models, their study identifies strong positive auto-correlations in Syrian cities and non-trivial cross-correlations across some of them. Researchers suggest that strong positive auto-correlations possibly reflects a sequence of attacks within short periods triggered by a single attack, as well as significant cross-correlation in some of the Syrian cities imply that deaths in one city were accompanied by deaths at another city.
Within a pattern recognition context, researchers (Klausen, Marks, & Zaman, 2016) from MIT Sloan developed a behavioural model to predict which Twitter users are likely belonged to the Islamic state group. Using data of approximately 5,000 Twitter users who were linked with Islamic state group members, they created a dataset of 1.3 million users by associating friends and followers of target users. At the same time, they monitored Twitter over few months to identify which profiles are getting suspended. Researchers claim that they were able to train a machine learning model that matched suspended accounts with the specifics of the profile and creating a framework to identify likely members of ISIL.
A similar research from (Ceron, Curini, & Iacus, 2018) examines over 25 million tweets in Arabic language when Islamic State was at its peak strength (between Jan 2014 to Jan 2015) and was expanding regions under its control. Researchers assessed the share of support from the online Arab community toward ISIS and investigated time time-granularity of tweets while linking the tweet opinions with daily events and geolocation of tweets. The outcome of their research finds a relationship between foreign fighters joining ISIS and online opinions across the regions.
One of the researches evaluates the targeting patterns and preferences of 480 terrorist groups that were operational between 1980 and 2011 in order to find the impact of longetivity of terrorist groups based on their lethality. Based on group-specific case studies on the Afghan and Pakistani Taliban and Harmony Database from Combat Terrorism Centre, researcher (Nawaz, 2017) uses Bivariate Probit Model to assess the endogenous relationship and finds significant correlationship between negative group reputation and group mortality. The researcher also uses Cox Proportional Hazard Model to estimate longetivity of group.
(Colaresi & Mahmood, 2017) carried out a research to identify and avoid the problem of overfitting sample data. Researchers used the models of civil war onset data and came up with a tool (R package: ModelCriticism) to illustrate how machine learning based research design can improve out of fold forecasting performance. Their study recommends making use of validation split along with train and test split to benefit from iterative model criticism.
Researchers (Muchlinski, Siroky, He, & Kocher, 2016/ed) use The Civil War Data (1945-2000) and compared the performance of Random Forests model with three different versions of logistic regression. The outcome of their study suggests that random forest model provides significantly more accurate predictions on the occurrences of rare events in out of sample data compared to logistic regression models on a chosen dataset. However in an experimental research to reproduce this claims, (Neunhoeffer & Sternberg, 2018) ran re-analysis and finds problematic usage of cross-validation strategy. They contest the claim and suggest that there is no evidence of significant predictive performance of random forest as claimed by the original authors.
2.1.3 GTD and machine learning in previous research
Addressing the issue of rare events, researchers (Clauset & Woodard, 2013) came up with statistical modelling approach to estimate future probability of large scale terrorist attack. Using the data from GTD and RAND-MIPT database between 1968-2007, and three different models i.e. power law, exponential distributions and log normal, researchers estimate the likelihood of observing 9/11 sized attack between 11-35%. Using the same procedure, researchers then make a data-driven statistical forecast of at least one similar event over the next decade.
In a study to identify determinants of variation in country compliance with financial counterterrorism, researcher (Lula, 2014) uses dataset on financial counterterrorism for the period 2004-2011 along with Global Terrorism Database. Researcher employs both quantitative and qualitative analysis in their approach and uses regression analysis (ordered logit model) to estimate the statistical significance of independent variables on target variable i.e. compliance rates. The outcome of this study suggests that intensity and magnitude of terror threat, rate of international terror attacks, rate of suicide (terror) attacks, and military capability variable does not have a statistically significant effect on country compliance with financial counterterrorism. Based on research findings, the author suggests that many of the assumptions made in the previous study in financial counterterrorism are incorrect.
A research from (Brennan, 2016) uses machine learning based approach to investigate terrorist incidents by country. This study makes use of regression techniques, Hidden Markov model, twitter outbreak detection algorithm, SURUS algorithm, as well as medical syndromic surveillance algorithms i.e EARSC based method and Farrington’s method to detect change in behaviour (in terms of terrorist incident or fatalities). The outcome of their study suggests that time-series aberration detection methods were highly interpretable and generalizable compared to traditional methods (regression and HMM) for analysing time series data.
Researcher (Block, 2016) carried out a study to identify characteristics of terrorist events specific to aircrafts and airports and came up with situation crime prevention framework to minimize such attacks. In particular, the researcher uses GTD data (2002-2014) specific to attacks involving airports/ aircraft that contains terrorist events related to 44 nations. In this study, Logistic Regression model is used to evaluate variables that are significantly associated with such attacks. Their research findings suggest that the likelihood of attacks against airports is mostly related to domestic terrorist groups and, explosives and suicide attacks as a type of attack. In contrast, attacks against aircraft are more associated with international terrorists groups.
In an effort to improve accuracy of classification algorithms, researchers (Mo, Meng, Li, & Zhao, 2017) uses GTD data and employs feature selection methods such as Minimal-redundancy maximal-relevancy (mRMR) and Maximal relevance (Max-Relevance). In this study, researchers use Support Vector Machine, Naive Bayes, and Logistic Regression algorithms and evaluate the performance of each model through classification precision and computational time. Their research finding suggests that feature selection methods improve the accuracy of the model and comparatively, Logistic Regression model with seven optimal feature subset achieves a classification precision of 78.41%.
A research from (Ding, Ge, Jiang, Fu, & Hao, 07AD–2017) also uses classification technique to evaluate risk of terrorist incident at global level using GTD and several other datasets. In particular, data comprising terror incidents between 1970 to 2015 was used to train and evaluate neural network (NNET), support vector machine (SVM), and random forest (RF) models. For performance evaluation, researchers used three-quarters of the randomly sampled data as a training set, and the remaining as a test set. The outcome of their study predicted the places where terror events might occur in 2015, with a success rate of 96.6%.
In a similar research within classification context and addressing the issue of class unbalance in order to predict rare events i.e. responsible group behind terror attack, researchers (Gundabathula & Vaidhehi, 2018) employ various classification algorithms in line with sampling technique to improve the model accuracy. In particular, this study was narrowed down to terrorist incidents in India and data used from GTD was between 1970-2015. Researchers used J48, IBK, Naive Bayes algorithms and an ensemble approach for the classification task. Finding from their study indicates the importance of using sampling technique which improves the accuracy of base models and suggests that an ensemble approach improves the overall accuracy of base models.
2.2 Literature gap and relevance
Review of the recent and relevant literature suggests that use of historical data from open source databases, and statistical modeling using time-series forecasting algorithms are commonly used approach to address the research questions related to “when and where”. A trend can be seen in the research study with a variety of new approaches such as feature selection, sampling technique, validation split etc to achieve better accuracy in classification algorithms. This is one of the most relevant aspects of this research project.
While some approach argues that prediction is a contentious issue and focuses on finding causal variables while neglecting model fit, there is an upward trend in an approach that uses diverse models, and out of fold method which also allows evaluating and comparing model performance. Similarly, a single model philosophy based on Occam’s razor principle is visible in some of the research however ensemble philosophy to make use of weak but diverse models to improve the overall accuracy is gaining popularity amongst research nowadays.
It is also observed that use of gradient boosting machines is not popular in scientific research despite the availability and practical use cases of highly efficient and open-source algorithms such as XGBoost and LightGBM which are widely used in machine learning competitions such as Kaggle. In contrast, traditional algorithms such as Random Forest, Logistic Regression, Naive Bayes, J48 etc. are often used in majority of research.
One important observation from the literature review is that code sharing is quite uncommon. Replication crisis is a major issue in scientific research. Despite the availability of a number of open source tools for reproducible research such as Jupyter notebook, rmarkdown or code repositories such as github, the majority of research papers lacks code sharing aspect.